Что такое потоки в процессоре
Процессоры, ядра и потоки. Топология систем
В этой статье я попытаюсь описать терминологию, используемую для описания систем, способных исполнять несколько программ параллельно, то есть многоядерных, многопроцессорных, многопоточных. Разные виды параллелизма в ЦПУ IA-32 появлялись в разное время и в несколько непоследовательном порядке. Во всём этом довольно легко запутаться, особенно учитывая, что операционные системы заботливо прячут детали от не слишком искушённых прикладных программ. 
 Мобильные системы (телефоны, планшеты, ноутбуки) и большинство десктопов имеют один процессор. Рабочие станции и сервера иногда могут похвастаться двумя или больше процессорами на одной материнской плате.
Мобильные системы (телефоны, планшеты, ноутбуки) и большинство десктопов имеют один процессор. Рабочие станции и сервера иногда могут похвастаться двумя или больше процессорами на одной материнской плате. Поддержка нескольких центральных процессоров в одной системе требует многочисленных изменений в её дизайне. Как минимум, необходимо обеспечить их физическое подключение (предусмотреть несколько сокетов на материнской плате), решить вопросы идентификации процессоров (см. далее в этой статье, а также мою предыдущую заметку), согласования доступов к памяти и доставки прерываний (контроллер прерываний должен уметь маршрутизировать прерывания на несколько процессоров) и, конечно же, поддержки со стороны операционной системы. Я, к сожалению, не смог найти документального упоминания момента создания первой многопроцессорной системы на процессорах Intel, однако Википедия утверждает, что Sequent Computer Systems поставляла их уже в 1987 году, используя процессоры Intel 80386. Широко распространённой поддержка же нескольких чипов в одной системе становится доступной, начиная с Intel® Pentium.
Если процессоров несколько, то каждый из них имеет собственный разъём на плате. У каждого из них при этом имеются полные независимые копии всех ресурсов, таких как регистры, исполняющие устройства, кэши. Делят они общую память — RAM. Память может подключаться к ним различными и довольно нетривиальными способами, но это отдельная история, выходящая за рамки этой статьи. Важно то, что при любом раскладе для исполняемых программ должна создаваться иллюзия однородной общей памяти, доступной со всех входящих в систему процессоров. К взлёту готов! Intel® Desktop Board D5400XS Исторически многоядерность в Intel IA-32 появилась позже Intel® HyperThreading, однако в логической иерархии она идёт следующей.
К взлёту готов! Intel® Desktop Board D5400XS Исторически многоядерность в Intel IA-32 появилась позже Intel® HyperThreading, однако в логической иерархии она идёт следующей. Казалось бы, если в системе больше процессоров, то выше её производительность (на задачах, способных задействовать все ресурсы). Однако, если стоимость коммуникаций между ними слишком велика, то весь выигрыш от параллелизма убивается длительными задержками на передачу общих данных. Именно это наблюдается в многопроцессорных системах — как физически, так и логически они находятся очень далеко друг от друга. Для эффективной коммуникации в таких условиях приходится придумывать специализированные шины, такие как Intel® QuickPath Interconnect. Энергопотребление, размеры и цена конечного решения, конечно, от всего этого не понижаются. На помощь должна прийти высокая интеграция компонент — схемы, исполняющие части параллельной программы, надо подтащить поближе друг к другу, желательно на один кристалл. Другими словами, в одном процессоре следует организовать несколько ядер, во всём идентичных друг другу, но работающих независимо.
Первые многоядерные процессоры IA-32 от Intel были представлены в 2005 году. С тех пор среднее число ядер в серверных, десктопных, а ныне и мобильных платформах неуклонно растёт. В отличие от двух одноядерных процессоров в одной системе, разделяющих только память, два ядра могут иметь также общие кэши и другие ресурсы, отвечающие за взаимодействие с памятью. Чаще всего кэши первого уровня остаются приватными (у каждого ядра свой), тогда как второй и третий уровень может быть как общим, так и раздельным. Такая организация системы позволяет сократить задержки доставки данных между соседними ядрами, особенно если они работают над общей задачей.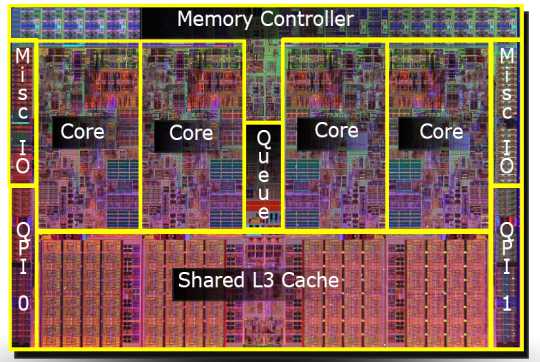 Микроснимок четырёхядерного процессора Intel с кодовым именем Nehalem. Выделены отдельные ядра, общий кэш третьего уровня, а также линки QPI к другим процессорам и общий контроллер памяти. До примерно 2002 года единственный способ получить систему IA-32, способную параллельно исполнять две или более программы, состоял в использовании именно многопроцессорных систем. В Intel® Pentium® 4, а также линейке Xeon с кодовым именем Foster (Netburst) была представлена новая технология — гипертреды или гиперпотоки, — Intel® HyperThreading (далее HT). Ничто не ново под луной. HT — это частный случай того, что в литературе именуется одновременной многопоточностью (simultaneous multithreading, SMT). В отличие от «настоящих» ядер, являющихся полными и независимыми копиями, в случае HT в одном процессоре дублируется лишь часть внутренних узлов, в первую очередь отвечающих за хранение архитектурного состояния — регистры. Исполнительные же узлы, ответственные за организацию и обработку данных, остаются в единственном числе, и в любой момент времени используются максимум одним из потоков. Как и ядра, гиперпотоки делят между собой кэши, однако начиная с какого уровня — это зависит от конкретной системы.
Микроснимок четырёхядерного процессора Intel с кодовым именем Nehalem. Выделены отдельные ядра, общий кэш третьего уровня, а также линки QPI к другим процессорам и общий контроллер памяти. До примерно 2002 года единственный способ получить систему IA-32, способную параллельно исполнять две или более программы, состоял в использовании именно многопроцессорных систем. В Intel® Pentium® 4, а также линейке Xeon с кодовым именем Foster (Netburst) была представлена новая технология — гипертреды или гиперпотоки, — Intel® HyperThreading (далее HT). Ничто не ново под луной. HT — это частный случай того, что в литературе именуется одновременной многопоточностью (simultaneous multithreading, SMT). В отличие от «настоящих» ядер, являющихся полными и независимыми копиями, в случае HT в одном процессоре дублируется лишь часть внутренних узлов, в первую очередь отвечающих за хранение архитектурного состояния — регистры. Исполнительные же узлы, ответственные за организацию и обработку данных, остаются в единственном числе, и в любой момент времени используются максимум одним из потоков. Как и ядра, гиперпотоки делят между собой кэши, однако начиная с какого уровня — это зависит от конкретной системы. Я не буду пытаться объяснить все плюсы и минусы дизайнов с SMT вообще и с HT в частности. Интересующийся читатель может найти довольно подробное обсуждение технологии во многих источниках, и, конечно же, в Википедии. Однако отмечу следующий важный момент, объясняющий текущие ограничения на число гиперпотоков в реальной продукции.
В каких случаях наличие «нечестной» многоядерности в виде HT оправдано? Если один поток приложения не в состоянии загрузить все исполняющие узлы внутри ядра, то их можно «одолжить» другому потоку. Это типично для приложений, имеющих «узкое место» не в вычислениях, а при доступе к данным, то есть часто генерирующих промахи кэша и вынужденных ожидать доставку данных из памяти. В это время ядро без HT будет вынуждено простаивать. Наличие же HT позволяет быстро переключить свободные исполняющие узлы к другому архитектурному состоянию (т.к. оно как раз дублируется) и исполнять его инструкции. Это — частный случай приёма под названием latency hiding, когда одна длительная операция, в течение которой полезные ресурсы простаивают, маскируется параллельным выполнением других задач. Если приложение уже имеет высокую степень утилизации ресурсов ядра, наличие гиперпотоков не позволит получить ускорение — здесь нужны «честные» ядра. Типичные сценарии работы десктопных и серверных приложений, рассчитанных на машинные архитектуры общего назначения, имеют потенциал к параллелизму, реализуемому с помощью HT. Однако этот потенциал быстро «расходуется». Возможно, по этой причине почти на всех процессорах IA-32 число аппаратных гиперпотоков не превышает двух. На типичных сценариях выигрыш от использования трёх и более гиперпотоков был бы невелик, а вот проигрыш в размере кристалла, его энергопотреблении и стоимости значителен.Другая ситуация наблюдается на типичных задачах, выполняемых на видеоускорителях. Поэтому для этих архитектур характерно использование техники SMT с бóльшим числом потоков. Так как сопроцессоры Intel® Xeon Phi (представленные в 2010 году) идеологически и генеалогически довольно близки к видеокартам, на них может быть четыре гиперпотока на каждом ядре — уникальная для IA-32 конфигурация.
Из трёх описанных «уровней» параллелизма (процессоры, ядра, гиперпотоки) в конкретной системе могут отсутствовать некоторые или даже все. На это влияют настройки BIOS (многоядерность и многопоточность отключаются независимо), особенности микроархитектуры (например, HT отсутствовал в Intel® Core™ Duo, но был возвращён с выпуском Nehalem) и события при работе системы (многопроцессорные сервера могут выключать отказавшие процессоры в случае обнаружения неисправностей и продолжать «лететь» на оставшихся). Каким образом этот многоуровневый зоопарк параллелизма виден операционной системе и, в конечном счёте, прикладным приложениям?Далее для удобства обозначим количества процессоров, ядер и потоков в некоторой системе тройкой (x, y, z), где x — это число процессоров, y — число ядер в каждом процессоре, а z — число гиперпотоков в каждом ядре. Далее я буду называть эту тройку топологией — устоявшийся термин, мало что имеющий с разделом математики. Произведение p = xyz определяет число сущностей, именуемых логическими процессорами системы. Оно определяет полное число независимых контекстов прикладных процессов в системе с общей памятью, исполняющихся параллельно, которые операционная система вынуждена учитывать. Я говорю «вынуждена», потому что она не может управлять порядком исполнения двух процессов, находящихся на различных логических процессорах. Это относится в том числе к гиперпотокам: хотя они и работают «последовательно» на одном ядре, конкретный порядок диктуется аппаратурой и недоступен для наблюдения или управления программам.
Чаще всего операционная система прячет от конечных приложений особенности физической топологии системы, на которой она запущена. Например, три следующие топологии: (2, 1, 1), (1, 2, 1) и (1, 1, 2) — ОС будет представлять в виде двух логических процессоров, хотя первая из них имеет два процессора, вторая — два ядра, а третья — всего лишь два потока. 
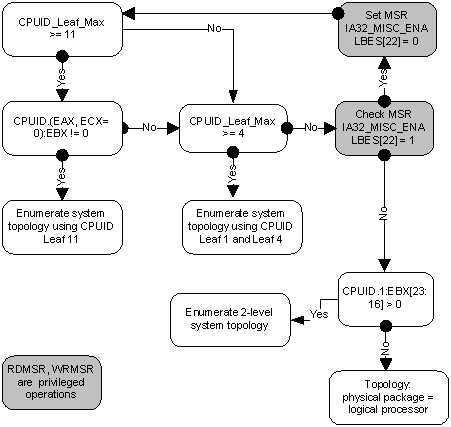 Я не буду здесь утомлять всеми подробностями отдельных частей этого алгоритма. Если возникнет интерес, то этому можно посвятить следующую часть этой статьи. Отошлю интересующегося читателя к [2], в которой этот вопрос разбирается максимально подробно. Здесь же я сначала кратко опишу, что такое APIC и как он связан с топологией. Затем рассмотрим работу с листом 0xB (одиннадцать в десятичном счислении), который на настоящий момент является последним словом в «апикостроении». Local APIC (advanced programmable interrupt controller) — это устройство (ныне входящее в состав процессора), отвечающее за работу с прерываниями, приходящими к конкретному логическому процессору. Свой собственный APIC есть у каждого логического процессора. И каждый из них в системе должен иметь уникальное значение APIC ID. Это число используется контроллерами прерываний для адресации при доставке сообщений, а всеми остальными (например, операционной системой) — для идентификации логических процессоров. Спецификация на этот контроллер прерываний эволюционировала, пройдя от микросхемы Intel 8259 PIC через Dual PIC, APIC и xAPIC к x2APIC. В настоящий момент ширина числа, хранящегося в APIC ID, достигла полных 32 бит, хотя в прошлом оно было ограничено 16, а ещё раньше — только 8 битами. Нынче остатки старых дней раскиданы по всему CPUID, однако в CPUID.0xB.EDX[31:0] возвращаются все 32 бита APIC ID. На каждом логическом процессоре, независимо исполняющем инструкцию CPUID, возвращаться будет своё значение. Значение APIC ID само по себе ничего не говорит о топологии. Чтобы узнать, какие два логических процессора находятся внутри одного физического (т.е. являются «братьями» гипертредами), какие два — внутри одного процессора, а какие оказались и вовсе в разных процессорах, надо сравнить их значения APIC ID. В зависимости от степени родства некоторые их биты будут совпадать. Эта информация содержится в подлистьях CPUID.0xB, которые кодируются с помощью операнда в ECX. Каждый из них описывает положение битового поля одного из уровней топологии в EAX[5:0] (точнее, число бит, которые нужно сдвинуть в APIC ID вправо, чтобы убрать нижние уровни топологии), а также тип этого уровня — гиперпоток, ядро или процессор, — в ECX[15:8].
Я не буду здесь утомлять всеми подробностями отдельных частей этого алгоритма. Если возникнет интерес, то этому можно посвятить следующую часть этой статьи. Отошлю интересующегося читателя к [2], в которой этот вопрос разбирается максимально подробно. Здесь же я сначала кратко опишу, что такое APIC и как он связан с топологией. Затем рассмотрим работу с листом 0xB (одиннадцать в десятичном счислении), который на настоящий момент является последним словом в «апикостроении». Local APIC (advanced programmable interrupt controller) — это устройство (ныне входящее в состав процессора), отвечающее за работу с прерываниями, приходящими к конкретному логическому процессору. Свой собственный APIC есть у каждого логического процессора. И каждый из них в системе должен иметь уникальное значение APIC ID. Это число используется контроллерами прерываний для адресации при доставке сообщений, а всеми остальными (например, операционной системой) — для идентификации логических процессоров. Спецификация на этот контроллер прерываний эволюционировала, пройдя от микросхемы Intel 8259 PIC через Dual PIC, APIC и xAPIC к x2APIC. В настоящий момент ширина числа, хранящегося в APIC ID, достигла полных 32 бит, хотя в прошлом оно было ограничено 16, а ещё раньше — только 8 битами. Нынче остатки старых дней раскиданы по всему CPUID, однако в CPUID.0xB.EDX[31:0] возвращаются все 32 бита APIC ID. На каждом логическом процессоре, независимо исполняющем инструкцию CPUID, возвращаться будет своё значение. Значение APIC ID само по себе ничего не говорит о топологии. Чтобы узнать, какие два логических процессора находятся внутри одного физического (т.е. являются «братьями» гипертредами), какие два — внутри одного процессора, а какие оказались и вовсе в разных процессорах, надо сравнить их значения APIC ID. В зависимости от степени родства некоторые их биты будут совпадать. Эта информация содержится в подлистьях CPUID.0xB, которые кодируются с помощью операнда в ECX. Каждый из них описывает положение битового поля одного из уровней топологии в EAX[5:0] (точнее, число бит, которые нужно сдвинуть в APIC ID вправо, чтобы убрать нижние уровни топологии), а также тип этого уровня — гиперпоток, ядро или процессор, — в ECX[15:8]. 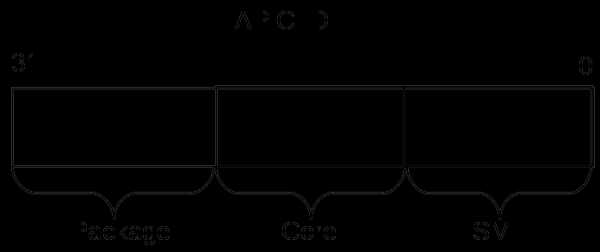
В Linux информация о топологии содержится в псевдофайле /proc/cpuinfo, а также выводе команды dmidecode. В примере ниже я фильтрую содержимое cpuinfo на некоторой четырёхядерной системе без HT, оставляя только записи, относящиеся к топологии:
Скрытый текстggg@shadowbox:~$ cat /proc/cpuinfo |grep 'processor\|physical\ id\|siblings\|core\|cores\|apicid' processor : 0 physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 processor : 1 physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 1 initial apicid : 1 processor : 2 physical id : 0 siblings : 4 core id : 1 cpu cores : 2 apicid : 2 initial apicid : 2 processor : 3 physical id : 0 siblings : 4 core id : 1 cpu cores : 2 apicid : 3 initial apicid : 3 В FreeBSD топология сообщается через механизм sysctl в переменной kern.sched.topology_spec в виде XML:Скрытый текстuser@host:~$ sysctl kern.sched.topology_spec kern.sched.topology_spec: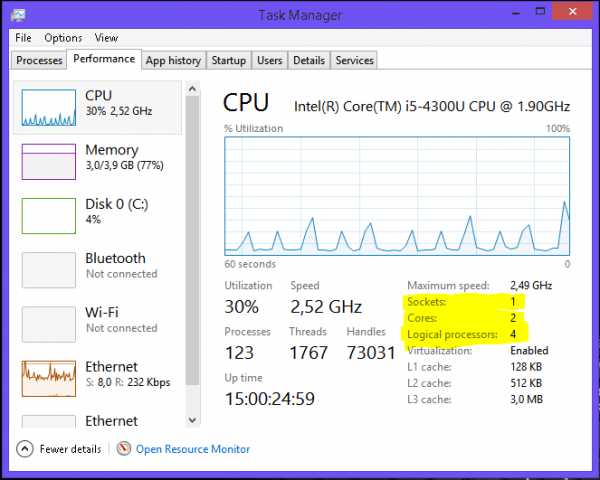
Также их предоставляет консольная утилита Sysinternals Coreinfo и API вызов GetLogicalProcessorInformation.
Проиллюстрирую ещё раз отношения между понятиями «процессор», «ядро», «гиперпоток» и «логический процессор» на нескольких примерах.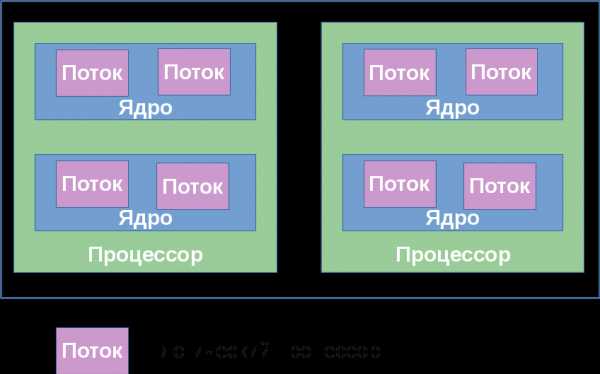
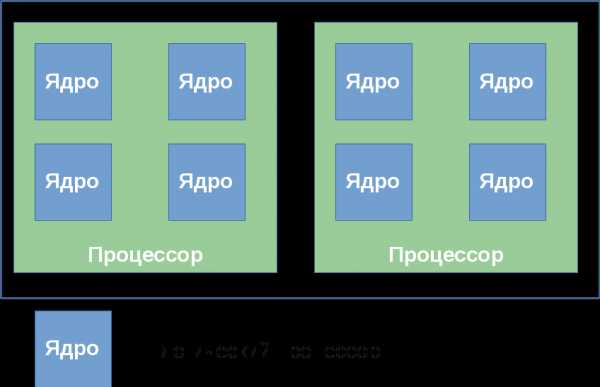
 В этот раздел я вынес некоторые курьёзы, возникающие из-за многоуровневой организации логических процессоров. Как я уже упоминал, кэши в процессоре тоже образуют иерархию, и она довольно сильно связано с топологией ядер, однако не определяется ей однозначно. Для определения того, какие кэши для каких логических процессоров общие, а какие нет, используется вывод CPUID.4 и её подлистов. Некоторые программные продукты поставляются числом лицензий, определяемых количеством процессоров в системе, на которой они будут использоваться. Другие — числом ядер в системе. Наконец, для определения числа лицензий число процессоров может умножаться на дробный «core factor», зависящий от типа процессора! Системы виртуализации, способные моделировать многоядерные системы, могут назначить виртуальным процессорам внутри машины произвольную топологию, не совпадающую с конфигурацией реальной аппаратуры. Так, внутри хозяйской системы (1, 2, 2) некоторые известные системы виртуализации по умолчанию выносят все логические процессоры на верхний уровень, т.е. создают конфигурацию (4, 1, 1). В сочетании с особенностями лицензирования, зависящими от топологии, это может порождать забавные эффекты. Спасибо за внимание!
В этот раздел я вынес некоторые курьёзы, возникающие из-за многоуровневой организации логических процессоров. Как я уже упоминал, кэши в процессоре тоже образуют иерархию, и она довольно сильно связано с топологией ядер, однако не определяется ей однозначно. Для определения того, какие кэши для каких логических процессоров общие, а какие нет, используется вывод CPUID.4 и её подлистов. Некоторые программные продукты поставляются числом лицензий, определяемых количеством процессоров в системе, на которой они будут использоваться. Другие — числом ядер в системе. Наконец, для определения числа лицензий число процессоров может умножаться на дробный «core factor», зависящий от типа процессора! Системы виртуализации, способные моделировать многоядерные системы, могут назначить виртуальным процессорам внутри машины произвольную топологию, не совпадающую с конфигурацией реальной аппаратуры. Так, внутри хозяйской системы (1, 2, 2) некоторые известные системы виртуализации по умолчанию выносят все логические процессоры на верхний уровень, т.е. создают конфигурацию (4, 1, 1). В сочетании с особенностями лицензирования, зависящими от топологии, это может порождать забавные эффекты. Спасибо за внимание! habrahabr.ru
Как узнать сколько потоков у процессора
Процессор является ключевым элементом компьютера, который отвечает за обработку информации. Она может находиться как непосредственно в памяти самого вычислителя, так и в памяти других составляющих машины.
Каждый процесс устройства проходит через процессор. Например, в него видеокарта передает обработанные графические данные. Он считается ключевым, в том числе потому, что даже если карта имеет высокую производительность, а процессор не очень мощный, то он будет не в состоянии обрабатывать информацию с той скоростью, с которой она поступает из видеокарты.
Таким образом, производственные способности просто нивелируются. Это явление получило название bottleneck, что в переводе значит «узкое место» или «узкая шея».
Прежде чем говорить о данной проблеме , стоит уточнить само определение этого термина. Сама технология носит название Hyper-threading, в источниках часто встречается аббревиатура HT.
Сразу стоит оговориться, что количество потоков процессора всегда остается неизменным и увеличить его никак нельзя. Потоки условно принято считать теми же ядрами, только не физическими, а виртуальными. Почему так, а не иначе, подробно описано ниже.
Само ядро – это непосредственно тот элемент, который отвечает за математические вычисления, согласно принятому в нем алгоритму. Процессор можно назвать своего рода «коробкой» для ядер, он объединяет их и обеспечивает взаимодействие с остальными компонентами системы.
Коротко по сути и маленькая предыстория
Технология Hyper-threading дает возможность хранения двух потоков одновременно. Поэтому при использовании операционной системы Windows, процессор на 2 ядра имеет в своем активе 4 потока. Такие вычислители еще часто называют процессорами, поддерживающими Hyper-treading (гипертрейдинг).
Дорогие и высокопроизводительные процессоры содержат ядра и потоки. Многие считают, что это смежные понятия, однако это не до конца верно. Впервые потоки появились еще в те времена, когда на рынке технологий царствовал Pentium 4.
Среди некоторых пользователей бытовало мнение, что они отрицательно сказываются на производительности. Это утверждение является несколько ошибочным, ведь дело в оптимизации программного обеспечения.
Программ, которые могли корректно использовать данное преимущество было не много, если вообще были. Эта разработка находилась на стадии, своего рода, полевых исследований.
Система сама все о себе знает
Когда пользователь взаимодействует с конкретными программами компьютера, это вовсе не значит, что больше машина ничего не делает. Есть служебные задачи и фоновые процессы, выполнение которых происходит незаметно на первый взгляд.
Чтобы узнать подробную информацию в операционной системе Windows существует «Диспетчер задач», который в том числе покажет, сколько ресурсов компьютера используется в данное время.
Этот инструмент удобен, часто бывает полезен и обладает интуитивно понятным интерфейсом. Для того, чтобы открыть это приложение, нужно одновременно зажать клавиши Ctrl+Alt+Delete.
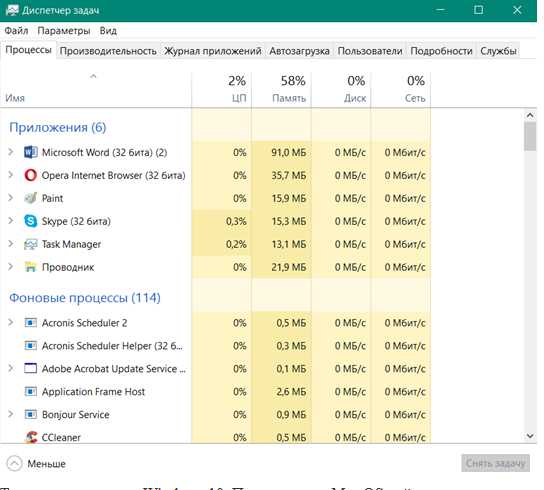
Так это выглядит на Windows 10. Пользователи Mac OS найдут на своем компьютере утилиту «Принудительное завершение программ», которое легко вызвать при помощи клавиш cmd alt Esc. Она также дает возможность закрыть программу, которая перестала отвечать. Еще одна популярная операционная система с открытым исходным кодом, Linux, тоже содержит диспетчер задач, только называется он по-другому – «Системный монитор».
Добраться до него помогут 3 простых шага:
- Меню
- Системные утилиты
- Системный монитор
или можно воспользоваться командой
gnome-system-monitor.
Функционал «Системного монитора» полностью соответствуют таковым в «Диспетчере задач» Windows и «Принудительному завершению программ» в операционной системе от компании Apple.
Почему так быстрее
Поток, обработавший одну порцию данных, ожидает получение другой, а если он не получает, то помогает другому потоку. Таким образом достигается максимальное быстродействие, за счет того, что все ресурсы компьютера используются рационально. Он, в какой-то степени, становится более гибким.
Количество потоков всегда вдвое больше, нежели количество ядер (при наличии «на борту» технологии HT). 2 ядра равнозначно 4-ем потокам, 4 ядра равнозначно 8-и потокам. Алгоритм просчета не может бить иным. Авторство разработки принадлежит компании Intel, являющейся лидером в производстве процессоров на массовом потребительском рынке.
Таким образом, одно физическое реальное ядро состоит из двух виртуальных ядер. Не только ОС, но и программы, которые установлены на устройстве, видят это и используют открытый перед ними потенциал возможностей. Если программа поддерживает многопоточность, то работать она будет намного быстрее.
Пошаговое руководство для новичков
Соответственно, чтобы узнать количество потоков, необходимо выяснить количество ядер, содержащихся в процессоре. Для это есть 3 (как минимум) способа:
1. Документация устройства, в которой подробно указаны характеристики. 2. Интернет, где можно ввести модель ноутбука и посмотреть, что находится у него «под капотом».
3. Или же в этом может помочь уже упомянутый ранее «Диспетчер задач», в котором нужно выбрать пункт меню «Производительность».
vacenko.ru
Технология Hyper-Threading от Intel
В прошлом мы рассказывали о технологии одновременной многопоточности (Simultaneous Multi-Threading - SMT), которая применяется в процессорах Intel. И хотя первоначально она создавалась под кодовым именем "технология Джексона" (Jackson Technology) как возможный, вероятный вариант, Intel официально анонсировала свою технологию на форуме IDF прошлой осенью. Кодовое имя Jackson было заменено более подходящим Hyper-Threading. Итак, для того чтобы разобраться, как работает новая технология, нам нужны кое-какие первоначальные знания. А именно, нам нужно знать, что такое поток, как выполняются эти потоки. Почему работает приложение? Как процессор узнает, какие операции и над какими данными он должен совершать? Вся эта информация содержится в откомпилированном коде выполняемого приложения. И как только приложение получает от пользователя какую-либо команду, какие-либо данные, – процессору сразу же отправляются потоки, в результате чего он и выполняет то, что должен выполнить в ответ на запрос пользователя. С точки зрения процессора, поток – это набор инструкций, которые необходимо выполнить. Когда в вас попадает снаряд в Quake III Arena, или когда вы открываете документ Microsoft Word, процессору посылается определенный набор инструкций, которые он должен выполнить.
Процессор точно знает, где брать эти инструкции. Для этой цели предназначен редко упоминаемый регистр, называемый счетчиком команд (Program Counter, PC). Этот регистр указывает на место в памяти, где хранится следующая для выполнения команда. Когда поток отправляется на процессор, адрес памяти потока загружается в этот счетчик команд, чтобы процессор знал, с какого именно места нужно начать выполнение. После каждой инструкции значение этого регистра увеличивается. Весь этот процесс выполняется до завершения потока. По окончании выполнения потока, в счетчик команд заносится адрес следующей инструкции, которую нужно выполнить. Потоки могут прерывать друг друга, при этом процессор запоминает значение счетчика команд в стеке и загружает в счетчик новое значение. Но ограничение в этом процессе все равно существует – в каждую единицу времени можно выполнять лишь один поток.
Существует общеизвестный способ решения данной проблемы. Заключается он в использовании двух процессоров – если один процессор в каждый момент времени может выполнять один поток, то два процессора за ту же единицу времени могут выполнять уже два потока. Отметим, что этот способ не идеален. При нем возникает множество других проблем. С некоторыми, вы уже, вероятно, знакомы. Во-первых, несколько процессоров всегда дороже, чем один. Во-вторых, управлять двумя процессорами тоже не так-то просто. Кроме того, не стоит забывать о разделении ресурсов между процессорами. Например, до появления чипсета AMD 760MP, все x86 платформы с поддержкой многопроцессорности разделяли всю пропускную способность системной шины между всеми имеющимися процессорами. Но основной недостаток в другом – для такой работы и приложения, и сама операционная система должны поддерживать многопроцессорность. Способность распределить выполнение нескольких потоков по ресурсам компьютера часто называют многопоточностью. При этом и операционная система должна поддерживать многопоточность. Приложения также должны поддерживать многопоточность, чтобы максимально эффективно использовать ресурсы компьютера. Не забывайте об этом, когда мы будем рассматривать ещё один подход решения проблемы многопоточности, новую технологию Hyper-Threading от Intel.
Производительности всегда мало
Об эффективности всегда много говорят. И не только в корпоративном окружении, в каких-то серьезных проектах, но и в повседневной жизни. Говорят, homo sapiens лишь частично задействуют возможности своего мозга. То же самое относится и к процессорам современных компьютеров.
Взять, к примеру, Pentium 4. Процессор обладает, в общей сложности, семью исполнительными устройствами, два из которых могут работать с удвоенной скоростью – две операции (микрооперации) за такт. Но в любом случае, вы бы не нашли программы, которая смогла бы заполнить инструкциями все эти устройства. Обычные программы обходятся несложными целочисленными вычислениями, да несколькими операциями загрузки и хранения данных, а операции с плавающей точкой остаются в стороне. Другие же программы (например, Maya) главным образом загружают работой устройства для операций с плавающей точкой.
Чтобы проиллюстрировать ситуацию, давайте вообразим себе процессор с тремя исполнительными устройствами: арифметико-логическим (целочисленным – ALU), устройством для работы с плавающей точкой (FPU), и устройством загрузки/хранения (для записи и чтения данных из памяти). Кроме того, предположим, что наш процессор может выполнять любую операцию за один такт и может распределять операции по всем трем устройствам одновременно. Давайте представим, что к этому процессору на выполнение отправляется поток из следующих инструкций:
1+1 10+1
Сохранить предыдущий результат
Рисунок ниже иллюстрирует уровень загруженности исполнительных устройств (серым цветом обозначается незадействованное устройство, синим – работающее устройство):
Итак, вы видите, что в каждый такт используется только 33% всех исполнительных устройств. В этот раз FPU остается вообще незадействованным. В соответствии с данными Intel, большинство программ для IA-32 x86 используют не более 35% исполнительных устройств процессора Pentium 4.
Представим себе ещё один поток, отправим его на выполнение процессору. На этот раз он будет состоять из операций загрузки данных, сложения и сохранения данных. Они будут выполняться в следующем порядке:
И снова загруженность исполнительных устройств составляет лишь на 33%.
Хорошим выходом из данной ситуации будет параллелизм на уровне инструкций (Instruction Level Parallelism - ILP). В этом случае одновременно выполняются сразу нескольких инструкций, поскольку процессор способен заполнять сразу несколько параллельных исполнительных устройств. К сожалению, большинство x86 программ не приспособлены к ILP в должной степени. Поэтому приходится изыскивать другие способы увеличения производительности. Так, например, если бы в системе использовалось сразу два процессора, то можно было бы одновременно выполнять сразу два потока. Такое решение называется параллелизмом на уровне потоков (thread-level parallelism, TLP). К слову сказать, такое решение достаточно дорогое.
Какие же ещё существуют способы увеличения исполнительной мощи современных процессоров архитектуры x86?
Hyper-Threading
Проблема неполного использования исполнительных устройств связана с несколькими причинами. Вообще говоря, если процессор не может получать данные с желаемой скоростью (это происходит в результате недостаточной пропускной способности системной шины и шины памяти), то исполнительные устройства будут использоваться не так эффективно. Кроме того, существует ещё одна причина – недостаток параллелизма на уровне инструкций в большинстве потоков выполняемых команд.
В настоящее время большинство производителей улучшают скорость работы процессоров путем увеличения тактовой частоты и размеров кэша. Конечно, таким способом можно увеличить производительность, но все же потенциал процессора не будет полностью задействован. Если бы мы могли одновременно выполнять несколько потоков, то мы смогли бы использовать процессор куда более эффективно. Именно в этом и заключается суть технологии Hyper-Threading.
Hyper-Threading – это название технологии, существовавшей и ранее вне x86 мира, технологии одновременной многопоточности (Simultaneous Multi-Threading, SMT). Идея этой технологии проста. Один физический процессор представляется операционной системе как два логических процессора, и операционная система не видит разницы между одним SMT процессором или двумя обычными процессорами. В обоих случаях операционная система направляет потоки как на двухпроцессорную систему. Далее все вопросы решаются на аппаратном уровне.
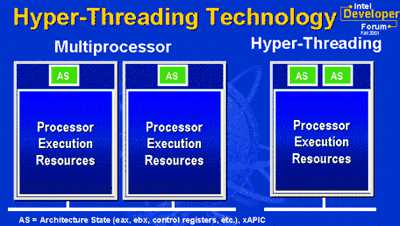
В процессоре с Hyper-Threading каждый логический процессор имеет свой собственный набор регистров (включая и отдельный счетчик команд), а чтобы не усложнять технологию, в ней не реализуется одновременное выполнение инструкций выборки/декодирования в двух потоках. То есть такие инструкции выполняются поочередно. Параллельно же выполняются лишь обычные команды.
Официально технология была объявлена на форуме Intel Developer Forum прошлой осенью. Технология демонстрировалась на процессоре Xeon, где проводился рендеринг с помощью Maya. В этом тесте Xeon с Hyper-Threading показал на 30% лучшие результаты, чем стандартный Xeon. Приятный прирост производительности, но больше всего интересно то, что технология уже присутствует в ядрах Pentium 4 и Xeon, только она выключена.
Технология пока ещё не выпущена, однако те из вас, кто приобрел 0,13 мкм Xeon, и установил этот процессор на платы с обновленным BIOS, наверняка были удивлены, увидев в BIOS опцию включения/отключения Hyper-Threading.
А пока Intel будет оставлять опцию Hyper-Threading отключенной по умолчанию. Впрочем, для ее включения достаточно просто обновить BIOS. Все это касается рабочих станций и серверов, что же до рынка персональных компьютеров, в ближайшем будущем у компании планов касательно этой технологии не имеется. Хотя возможно, производители материнских плат предоставят возможность включить Hyper-Threading с помощью специального BIOS.
Остается очень интересный вопрос, почему Intel хочет оставить эту опцию выключенной?
Углубляемся в технологию
Помните те два потока из предыдущих примеров? Давайте на этот раз предположим, что наш процессор оснащен Hyper-Threading. Посмотрим, что получится, если мы попытаемся одновременно выполнить эти два потока:
Как и ранее, синие прямоугольники указывают на выполнение инструкции первого потока, а зеленые - на выполнение инструкции второго потока. Серые прямоугольники показывают незадействованные исполнительные устройства, а красные - конфликт, когда на одно устройство пришло сразу две разных инструкции из разных потоков.
Итак, что же мы видим? Параллелизм на уровне потоков дал сбой – исполнительные устройства стали использоваться ещё менее эффективно. Вместо параллельного выполнения потоков, процессор выполняет их медленнее, чем если бы он выполнял их без Hyper-Threading. Причина довольно проста. Мы пытались одновременно выполнить сразу два очень похожих потока. Ведь оба они состоят из операций по загрузке/сохранению и операций сложения. Если бы мы параллельно запускали "целочисленное" приложение и приложение, работающее с плавающей точкой, мы бы оказались куда в лучшей ситуации. Как видим, эффективность Hyper-Threading сильно зависит от вида нагрузки на ПК.
В настоящий момент, большинство пользователей ПК используют свой компьютер примерно так, как описано в нашем примере. Процессор выполняет множество очень схожих операций. К сожалению, когда дело доходит до однотипных операций, возникают дополнительные сложности с управлением. Случаются ситуации, когда исполнительных устройств нужного типа уже не осталось, а инструкций, как назло, вдвое больше обычного. В большинстве случаев, если бы процессоры домашних компьютеров использовали технологию Hyper-Threading, то производительность бы от этого не увеличилась, а может быть, даже снизилась на 0-10%.
На рабочих же станциях возможностей для увеличения производительности у Hyper-Threading больше. Но с другой стороны, все зависит от конкретного использования компьютера. Рабочая станция может означать как high-end компьютер для обработки 3D графики, так и просто сильно нагруженный компьютер.
Наибольший же прирост в производительности от использования Hyper-Threading наблюдается в серверных приложениях. Главным образом это объясняется широким разнообразием посылаемых процессору операций. Сервер баз данных, использующих транзакции, может работать на 20-30% быстрее при включенной опции Hyper-Threading. Чуть меньший прирост производительности наблюдается на веб-серверах и в других сферах.
Максимум эффективности от Hyper-Threading
Вы думаете, Intel разработала Hyper-Threading только лишь для своей линейки серверных процессоров? Конечно же, нет. Если бы это было так, они бы не стали впустую тратить место на кристалле других своих процессоров. По сути, архитектура NetBurst, использующаяся в Pentium 4 и Xeon, как нельзя лучше подходит для ядра с поддержкой одновременной многопоточности. Давайте ещё раз представим себе процессор. На этот раз в нем будет ещё одно исполнительное устройство – второе целочисленное устройство. Посмотрим, что случится, если потоки будут выполняться обоими устройствами:
С использованием второго целочисленного устройства, единственный конфликт случился только на последней операции. Наш теоретический процессор в чем-то похож на Pentium 4. В нем имеется целых три целочисленных устройства (два ALU и одно медленное целочисленное устройство для циклических сдвигов). А что ещё более важно, оба целочисленных устройства Pentium 4 способны работать с двойной скоростью – выполнять по две микрооперации за такт. А это, в свою очередь, означает, что любое из этих двух целочисленных устройств Pentium 4/Xeon могло выполнить те две операции сложения из разных потоков за один такт.
Но это не решает нашей проблемы. Было бы мало смысла просто добавлять в процессор дополнительные исполнительные устройства с целью увеличения производительности от использования Hyper-Threading. С точки зрения занимаемого на кремнии пространства это было бы крайне дорого. Вместо этого, Intel предложила разработчикам оптимизировать программы под Hyper-Threading.
Используя инструкцию HALT, можно приостановить работу одного из логических процессоров, и тем самым увеличить производительность приложений, которые не выигрывают от Hyper-Threading. Итак, приложение не станет работать медленнее, вместо этого один из логических процессоров будет остановлен, и система будет работать на одном логическом процессоре – производительность будет такой же, что и на однопроцессорных компьютерах. Затем, когда приложение сочтет, что от Hyper-Threading оно выиграет в производительности, второй логический процессор просто возобновит свою работу.
На веб-сайте Intel имеется презентация, описывающая, как именно необходимо программировать, чтобы извлечь из Hyper-Threading максимум выгоды.
Выводы
Хотя мы все были крайне обрадованы, когда до нас дошли слухи об использовании Hyper-Threading в ядрах всех современных Pentium 4/Xeon, все же это не будет бесплатной производительностью на все случаи жизни. Причины ясны, и технологии предстоит преодолеть ещё многое, прежде чем мы увидим Hyper-Threading, работающую на всех платформах, включая домашние компьютеры. А при поддержке разработчиков, технология определенно может оказаться хорошим союзником Pentium 4, Xeon, и процессорам будущего поколения от Intel.
При существующих ограничениях и при имеющейся технологии упаковки, Hyper-Threading кажется более разумным выбором для потребительского рынка, чем, например, подход AMD в SledgeHammer – в этих процессорах используется целых два ядра. И до тех пор, пока не станут совершенными технологии упаковки, такие как Bumpless Build-Up Layer, стоимость разработки многоядерных процессоров может оказаться слишком высокой.
Интересно заметить, насколько разными стали AMD и Intel за последние несколько лет. Ведь когда-то AMD практически копировала процессоры Intel. Теперь же компании выработали принципиально иные подходы к будущим процессорам для серверов и рабочих станций. AMD на самом деле проделала очень длинный путь. И если в процессорах Sledge Hammer действительно будут использоваться два ядра, то по производительности такое решение будет эффективнее, чем Hyper-Threading. Ведь в этом случае кроме удвоения количества всех исполнительных устройств снимаются проблемы, которые мы описали выше.
Hyper-Threading ещё некоторое время не появится на рынке обычных ПК, но при хорошей поддержке разработчиков, она может стать очередной технологией, которая опустится с серверного уровня до простых компьютеров.
Если вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
3dnews.ru
Чем процесс отличается от потока?… | БCБ на WordPress.com
В предыдущем посте, я рассказал Вам о понятии процесса в ОС. Сегодня же, я изложу более подробно о потоке, его отличии от процесса, а с помощью своих чудо-рук, ты сможешь создать консольный вариант Диспетчера задач (такой, немного убогий и без функции конечно…ну все-таки).
Первое, что надо усвоить — процесс состоит хотя бы из одного потока. В ОС каждому процессу соответствует адресное пространство и одиночный управляющий поток. Фактически это и определяет процесс.
С одной стороны, процесс можно рассматривать как способ объединения родственных ресурсов в одну группу. У процесса есть адресное пространство, содержащее текст программы и данные, а также другие ресурсы. Ресурсами являются открытые файлы, дочерние процессы, необработанные аварийные сообщения, обобработчики сигналов, учетная информация и многое другое. Гораздо проще управлять ресурсами, объединив их в форме процесса.
С другой стороны, процесс можно рассматривать как поток исполняемых кокоманд или просто поток. У потока есть счетчик команд, отслеживающий порядок выполнения действий. У него есть регистры, в которых хранятся текущие переменные. У него есть стек, содержащий протокол выполнения процесса, где на каждую процедуру, вызванную, но еще не вернувшуюся, отведен отдельный фрейм. Хотя поток должен исполняться внутри процесса, следует различать концепции потока и процесса. Процессы используются для группирования ресурсов, а потоки являются объектами, поочередно исполняющимися на центральном процессоре.
Концепция потоков добавляет к модели процесса возможность одновременного выполнения в одной и той же среде процесса нескольких программ, в достаточной степени независимых. Несколько потоков, работающих параллельно в одном процессе, аналогичны нескольким процессам, идущим параллельно на одном компьютере. В первом случае потоки разделяют адресное пространство, открытые файлы и другие ресурсы. Во втором случае процессы совместно пользуются физической памятью, дисками, принтерами и другими ресурсами. Потоки обладают некоторыми свойствами процессов, поэтому их иногда называют упрощенными процессами. Термин многопоточность также используется для описания использования нескольких потоков в одном процессе.
Любой поток состоит из двух компонентов:
объекта ядра, через который операционная система управляет потоком. Там же хранится статистическая информация о потоке(дополнительные потоки создаются также ядром); стека потока, который содержит параметры всех функций и локальные переменные, необходимые потоку для выполнения кода.
Подводя черту, закрепим: главное отличие процессов от потоков, состоит в том, что процессы изолированы друг от друга, так используют разные адресные пространства, а потоки, могут использовать одно и то же пространство (внутри процесса) при этом, выполняя действия не мешаяя друг другу. В этом и заключается удобство многопоточного программинга: разбив приложение на несколько последовательных потоков, мы можем увеличить производительность, упростить пользовательский интерфейс и добиться масштабируемости (если Ваше приложение установят на многопроцессорную систему, выполняя потоки на разных процах, ваша прога будет работать с аховой скоростью=)).
Я решил не рассказывать о многопоточном программировании сегодня, тем более что есть отличные мануалы по этой теме(ссылка внизу), а просто познакомиться с тем какие средства есть у CSharp для взаимодействия с потоками и процессами. А что рассказывать? MSDN в соседнее от окошка Class1.cs и вперед…=)
Понять пост не читая или для ленивых:
- Поток (thread) определяет последовательность исполнения кода в процессе.
- Процесс ничего не исполняет, он просто служит контейнером потоков.
- Потоки всегда создаются в контексте какого-либо процесса, и вся их жизнь проходит только в его границах.
- Потоки могут исполнять один и тот же код и манипулировать одними и теми же данными, а также совместно использовать описатели объектов ядра, поскольку таблица описателей создается не в отдельных потоках, а в процессах.
- Так как потоки расходуют существенно меньше ресурсов, чем процессы, старайтесь решать свои задачи за счет использования дополнительных потоков и избегайте создания новых процессов(но подходите к этому с умом).
Ссылка в тему: Основы многопоточного программирования на CSharp: albahari.com/threading/index.html
А почитать еще теории? Рихтер и Таненбаум…
seregaborzov.wordpress.com