Кэш процессора на что влияет
Как узнать кэш процессора?
Хеллоу ребята Поговорим о процессоре, а если быть точнее то о его кэше. Кэш у процессора может быть разный, например у меня сейчас Pentium G3220 (1150 сокет), это современный проц и в нем 3 мб кэша. Но при этом у старой модели Pentium D965 (775 сокет) кэша 4 мб. Но при этом G3220 в несколько раз быстрее чем D965, это я к тому, что кэш это хорошо, но главное чтобы кэш был современный. Кэш-память у старых процов намного медленнее, чем у новых, учтите это.
Давайте поговорим о некоторых устройствах, от которых зависит быстродействие. Вот смотрите, возьмем жесткий диск, есть ли у него кэш? Да, есть, но он мал, хотя и немного влияет на производительность. Потом идет что? Потом идет оперативная память, все с чем работает программа или процессор, все это помещается в оперативку. Если нет данных в оперативке, то они считываются с жесткого диска, а это очень медленно. А вот оперативка уже очень быстрая, ее может быть достаточно много. Но оперативка быстрая по сравнению с жестким диском, для процессора она все таки не очень быстрая и поэтому у последнего есть еще свой кэш, который уже реактивно супер быстрый!
Кэш процессора на что влияет? Именно в этом кэше процессор хранит то, чем часто пользуется, ну то есть всякие там команды и инструкции. Соответственно чем его больше, тем лучше, но это не совсем так. Вот сколько у вас кэша? Если не знаете, то я еще покажу как это узнать, тут все просто. Ну так вот, смотрите какая интересная ситуация, опять вернемся к старым процам. Вроде бы если много кэша, то это хорошо. Но есть процессор Q9650 (775 сокет), у которого 12 мб кэша, но он и близко не дотягивает до современных моделей Core i5 а то и Core i3. В i5 кэша в да раза меньше, то есть просто 6 мб, а в i3 его еще меньше — всего 3 мб.
Я понимаю что вообще современные процы куда быстрее, чем старые. Но я не о том. Кеш кэшу рознь, в топовом Q9650 просто медленный кэш по сравнению с процами на современном сокете. Поэтому толку от тех 12 мб никакого нет. Это все я к тому, что не гонитесь за количеством, гонитесь за качеством. Ну вот так. Это все я вам написал на заметку, надеюсь что вам пригодится
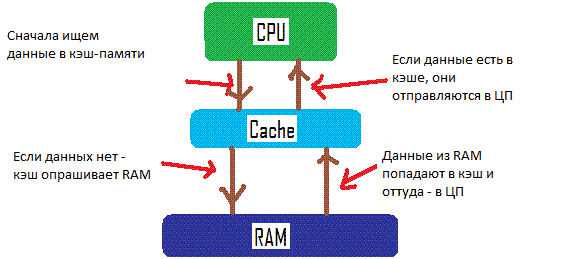
Вот на этой картинке по простому указан принцип работы кэша:
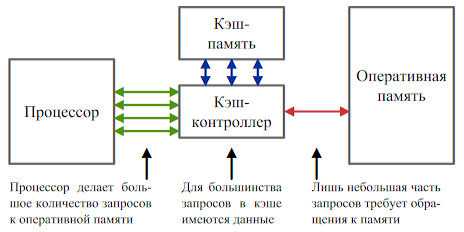
А вот другая картинка, тут также указано еще одно устройство, это контроллер, который как раз говорит о том есть ли данные в кэша или нет:
Кэш-память супер быстрая. Я не настолько разбираюсь в процах, но самому было бы интересно узнать, вот если бы этого кэша было… 100 мб.. или даже 1 гб.. был бы процессор быстрее? Это конечно даже сейчас фантастика, но уже сейчас есть процы с огромным количеством кэша.. около 30 мб или больше.. Я не уверен в этом, но вроде бы эта кэш-память очень дорогая и ее вообще сложно засунуть в проц, я имею ввиду большой обьем
Ну а теперь давайте я покажу как узнать сколько кэша в процессоре. Если у вас Windows 10, то это отлично, ибо она умеет показывать все кэши, там ведь есть три уровня. Хотя вроде бы самый главный это третий уровень, он же и самый большой. Итак, смотрите, открываете диспетчер задач и идете в на вкладку Производительность и вот нам на вкладке ЦП вы можете увидеть инфу о кэше, вот она:
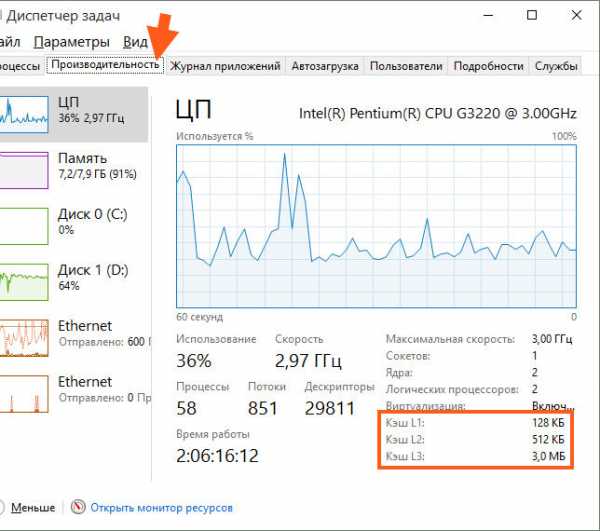
Вот тут видно, что у меня Pentium G3220, достаточно неплохой процессор, хоть и недорогой. Но реально быстрее многих моделей на 775 сокете, которые можно назвать околотоповые и которые имеют намного больше кэша… Вот такие дела…
Но скажу вот по чесноку, что это не есть четкий способ посмотреть сколько кэша у проца. Я советую использовать утилиту CPU-Z, если вы думаете типа: да это прога, нада ставить и все такое, а ну его… То стойте! Эту программу используют крутые оверлокеры, которые разгоняют свои процы. Утилита при установке не создает кучу файлов и на самом деле установка это просто распаковка проги в Program Files, потом cpuz.exe можно куда угодно скопировать и запускать, работать будет! Просто запустили и все, она собрала инфу и вы смотрите! Скачать ее можно легко в интернете, благо она есть на каждом углу. Только смотрите, чтобы вирусов не хапанули.. Для этого качайте например на софт-портале.. Так и пишите в поиске CPU-Z софт портал. Работает CPU-Z почти на всех версиях винды, ну кроме самих древних…
А вообще можете скачать вот на этом сайте: cpuid.com, я просто честно говоря не знал о нем и привык качать с других сайтов!
Ну что, надеюсь что скачать вы ее сможете без проблем. Теперь запускаете и вот тут вам о процессоре все как на ладони. Вот я запустил CPU-Z и вот что она показала о моем Pentium G3220:
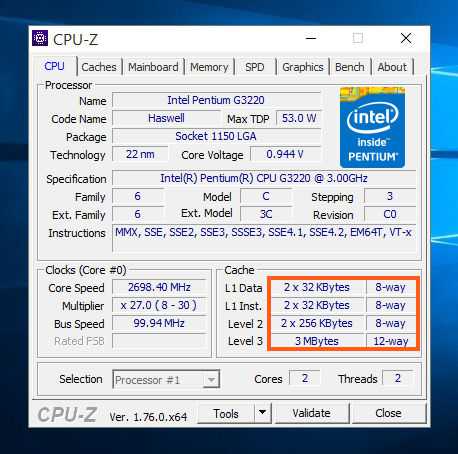
Там где я обвел рамочкой, вот там и отображается кэш. Что такое way, ну вот там написано 8-way, 12-way, ну вот что это я не знаю, уж простите. Но вот как видите тут четко видно не только кэш, но и другая инфа, частота, ядра (Cores) и потоки (Threads). Ну так вот, что еще интересно, так это то что тут показывает у вас один кэш или два. Ну вот у меня тут написано просто 3 MBytes, то есть у меня просто 3 мб кэша.
А вот например что касается топового Q9650, то там немного другая ситуация, хоть там и 12 мб кэша, но это по сути два блока по 6 мб и CPU-Z это определяет:
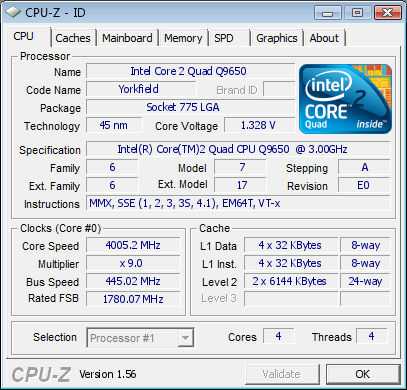
Тут кстати еще как видите есть разгон до 4 ГГц, это неплохо. Кстати такой разгон вполне может быть и на воздушном охлаждении. Но это уже совсем другая история…
Кстати еще что интересно, что в моделях на 775 сокете нет кэша третьего уровня L3… То есть там только L1 и L2.., а я не знал…
Так что вот такие вот дела. Надеюсь что все написал понятно. Еще раз повторю, не гонитесь вы за количеством. Вот я не очень жалею, но тем не менее.. Короче взял я и собрал себе комп на 1150 сокете. Ну думаю, все ништяк. Но как мне стало немного обидно, когда я узнал, что сокет 1151 вышел вот и что он стоит также, а то и чуть дешевле.. Но там реально быстрее процы уже идут.. Ну ладно. Я просто брал комп на века, но зато я обрадовался что моя плата, а это Asus Gryphon Z87 поддерживает процессоры на ядре Devil’s Canyon! Вот это был подарок, ведь раньше Intel заявляла что эти процессоры будут поддерживаться только чипсетом Z97, а я взял то блин Z87!
Короче вот такие дела
На этом все ребята. Надеюсь все у вас будет нормуль и данная инфа была вам полезной, удачи
На главную! кэш процессор 30.07.2016virtmachine.ru
Влияние кэш-памяти на производительность компьютера
Всем пользователям хорошо известны такие элементы компьютера, как процессор, отвечающий за обработку данных, а также оперативная память (ОЗУ или RAM), отвечающая за их хранение. Но далеко не все, наверное, знают, что существует и кэш-память процессора(Cache CPU), то есть оперативная память самого процессора (так называемая сверхоперативная память).

Функция кэш-памяти
В чем же состоит причина, которая побудила разработчиков компьютеров использовать специальную память для процессора? Разве возможностей ОЗУ для компьютера недостаточно?
Действительно, долгое время персональные компьютеры обходились без какой-либо кэш-памяти. Но, как известно, процессор – это самое быстродействующее устройство персонального компьютера и его скорость росла с каждым новым поколением CPU. В настоящее время его скорость измеряется миллиардами операций в секунду. В то же время стандартная оперативная память не столь значительно увеличила свое быстродействие за время своей эволюции.
Вообще говоря, существуют две основные технологии микросхем памяти – статическая память и динамическая память. Не углубляясь в подробности их устройства, скажем лишь, что статическая память, в отличие от динамической, не требует регенерации; кроме того, в статической памяти для одного бита информации используется 4-8 транзисторов, в то время как в динамической – 1-2 транзистора. Соответственно динамическая память гораздо дешевле статической, но в то же время и намного медленнее. В настоящее время микросхемы ОЗУ изготавливаются на основе динамической памяти.
Примерная эволюция соотношения скорости работы процессоров и ОЗУ:
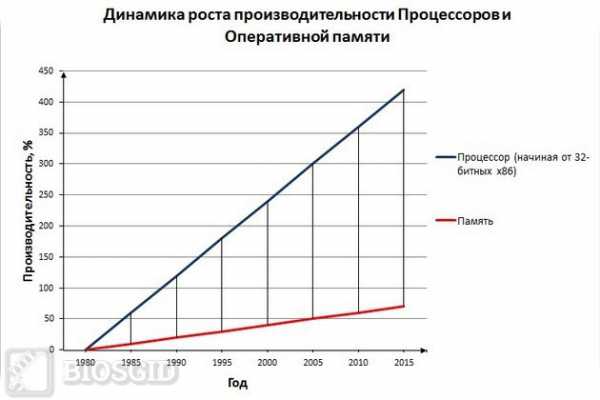
Таким образом, если бы процессор брал все время информацию из оперативной памяти, то ему пришлось бы ждать медлительную динамическую память, и он все время бы простаивал. В том же случае, если бы в качестве ОЗУ использовалась статическая память, то стоимость компьютера возросла бы в несколько раз.
Именно поэтому был разработан разумный компромисс. Основная часть ОЗУ так и осталась динамической, в то время как у процессора появилась своя быстрая кэш-память, основанная на микросхемах статической памяти. Ее объем сравнительно невелик – например, объем кэш-памяти второго уровня составляет всего несколько мегабайт. Впрочем, тут стоить вспомнить о том, что вся оперативная память первых компьютеров IBM PC составляла меньше 1 МБ.
Кроме того, на целесообразность внедрения технологии кэширования влияет еще и тот фактор, что разные приложения, находящиеся в оперативной памяти, по-разному нагружают процессор, и, как следствие, существует немало данных, требующих приоритетной обработки по сравнению с остальными.
История кэш-памяти
Строго говоря, до того, как кэш-память перебралась на персоналки, она уже несколько десятилетий успешно использовалась в суперкомпьютерах.
Впервые кэш-память объемом всего в 16 КБ появилась в ПК на базе процессора i80386. На сегодняшний день современные процессоры используют различные уровни кэша, от первого (самый быстрый кэш самого маленького объема – как правило, 128 КБ) до третьего (самый медленный кэш самого большого объема – до десятков МБ).
Сначала внешняя кэш-память процессора размещалась на отдельном чипе. Со временем, однако, это привело к тому, что шина, расположенная между кэшем и процессором, стала узким местом, замедляющим обмен данными. В современных микропроцессорах и первый, и второй уровни кэш-памяти находятся в самом ядре процессора.
Долгое время в процессорах существовали всего два уровня кэша, но в CPU Intel Itanium впервые появилась кэш-память третьего уровня, общая для всех ядер процессора. Существуют и разработки процессоров с четырехуровневым кэшем.
Архитектуры и принципы работы кэша
На сегодняшний день известны два основных типа организации кэш-памяти, которые берут свое начало от первых теоретических разработок в области кибернетики – принстонская и гарвардская архитектуры. Принстонская архитектура подразумевает единое пространство памяти для хранения данных и команд, а гарвардская – раздельное. Большинство процессоров персональных компьютеров линейки x86 использует раздельный тип кэш-памяти. Кроме того, в современных процессорах появился также третий тип кэш-памяти – так называемый буфер ассоциативной трансляции, предназначенный для ускорения преобразования адресов виртуальной памяти операционной системы в адреса физической памяти.
Упрощенно схему взаимодействия кэш-памяти и процессора можно описать следующим образом. Сначала происходит проверка наличия нужной процессору информации в самом быстром — кэше первого уровня, затем — в кэше второго уровня, и.т.д. Если же нужной информации в каком-либо уровне кэша не оказалось, то говорят об ошибке, или промахе кэша. Если информации в кэше нет вообще, то процессору приходится брать ее из ОЗУ или даже из внешней памяти (с жесткого диска).
Порядок поиска процессором информации в памяти:
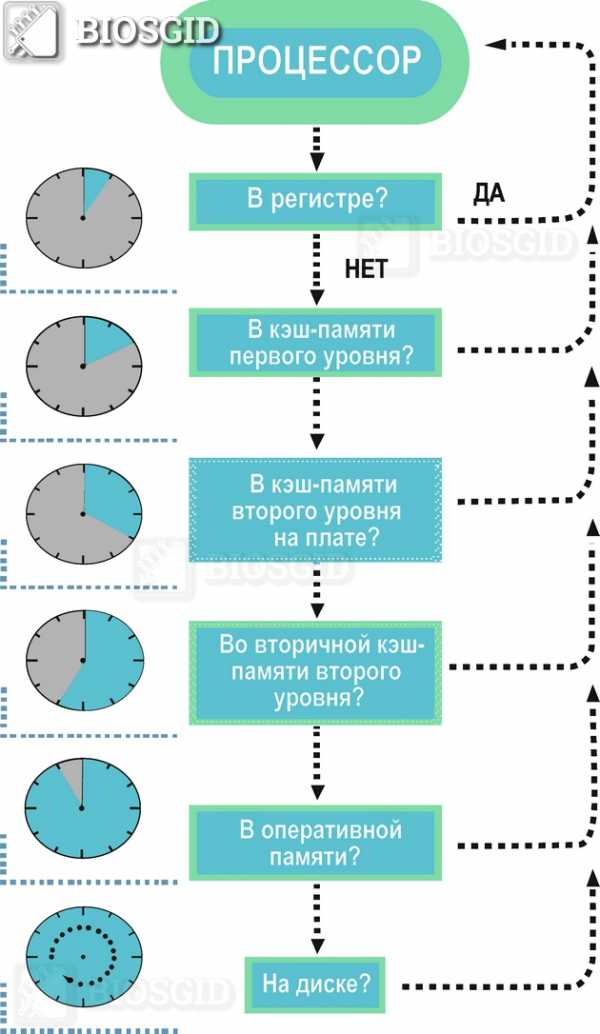 Именно таким образом Процессор осуществляет поиск инфоромации
Именно таким образом Процессор осуществляет поиск инфоромации Для управления работой кэш-памяти и ее взаимодействия с вычислительными блоками процессора, а также ОЗУ существует специальный контроллер.
Схема организации взаимодействия ядра процессора, кэша и ОЗУ:
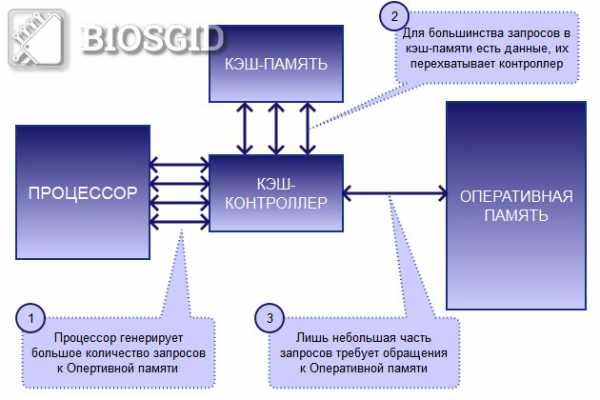 Кэш-контроллер является ключевым элементом связи процессора, ОЗУ и Кэш-памяти
Кэш-контроллер является ключевым элементом связи процессора, ОЗУ и Кэш-памяти Следует отметить, что кэширование данных – это сложный процесс, в ходе которого используется множество технологий и математических алгоритмов. Среди базовых понятий, применяющихся при кэшировании, можно выделить методы записи кэша и архитектуру ассоциативности кэш-памяти.
Методы записи кэша
Существует два основных метода записи информации в кэш-память:
- Метод write-back (обратная запись) – запись данных производится сначала в кэш, а затем, при наступлении определенных условий, и в ОЗУ.
- Метод write-through (сквозная запись) – запись данных производится одновременно в ОЗУ и в кэш.
Архитектура ассоциативности кэш-памяти
Архитектура ассоциативности кэша определяет способ, при помощи которого данные из ОЗУ отображаются в кэше. Существуют следующие основные варианты архитектуры ассоциативности кэширования:
- Кэш с прямым отображением – определенный участок кэша отвечает за определенный участок ОЗУ
- Полностью ассоциативный кэш – любой участок кэша может ассоциироваться с любым участком ОЗУ
- Смешанный кэш (наборно-ассоциативный)
На различных уровнях кэша обычно могут использоваться различные архитектуры ассоциативности кэша. Кэширование с прямым отображением ОЗУ является самым быстрым вариантом кэширования, поэтому эта архитектура обычно используется для кэшей большого объема. В свою очередь, полностью ассоциативный кэш обладает меньшим количеством ошибок кэширования (промахов).
Заключение
В этой статье вы познакомились с понятием кэш-памяти, архитектурой кэш-памяти и методами кэширования, узнали о том, как она влияет на производительность современного компьютера. Наличие кэш-памяти позволяет значительно оптимизировать работу процессора, уменьшить время его простоя, а, следовательно, и увеличить быстродействие всей системы.
biosgid.ru
Галерея эффектов кэшей процессоров
Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.
В этой статье мы рассмотрим ряд примеров иллюстрирующих различные особенности работы кэшей и их влияние на производительность. Примеры будут на C#, выбор языка и платформы не так сильно влияет на оценку производительности и конечные выводы. Естественно, в разумных пределах, если вы выберите язык, в котором чтение значения из массива равносильно обращению к хеш-таблице, никаких результатов пригодных к интерпретации вы не получите. Курсивом идут примечания переводчика.
- - - habracut - - -
Пример 1: доступ к памяти и производительность
Как вы думаете, насколько второй цикл быстрее первого? int[] arr = new int[64 * 1024 * 1024];// первый
for (int i = 0; i < arr.Length; i++) arr[i] *= 3;// второй
for (int i = 0; i < arr.Length; i += 16) arr[i] *= 3; Первый цикл умножает все значения массива на 3, второй цикл только каждое шестнадцатое значение. Второй цикл совершает только 6% работы первого цикла, но на современных машинах оба цикла выполняются примерно за равное время: 80 мс и 78 мс соответственно (на моей машине). Разгадка проста — доступ к памяти. Скорость работы этих циклов в первую очередь определяется скоростью работы подсистемы памяти, а не скоростью целочисленного умножения. Как мы увидим в следующем примере, количество обращений к оперативной памяти одинаково и в первом и во втором случае.Пример 2: влияние строк кэша
Копнём глубже — попробуем другие значения шага, не только 1 и 16: for (int i = 0; i < arr.Length; i += K /* шаг */ ) arr[i] *= 3; Вот время работы этого цикла для различных значений шага K: 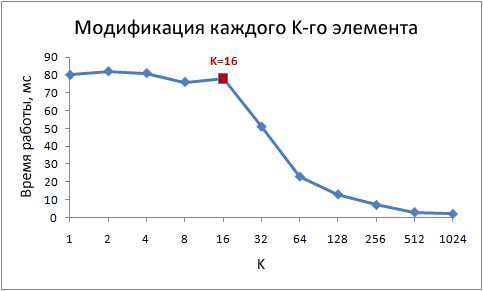
Обратите внимание, при значениях шага от 1 до 16 время работы практически не изменяется. Но при значениях больше 16, время работы уменьшается примерно вдвое каждый раз когда мы увеличиваем шаг в два раза. Это не означает, что цикл каким-то магическим образом начинает работать быстрее, просто количество итераций при этом так же уменьшается. Ключевой момент — одинаковое время работы при значениях шага от 1 до 16.
Причина этого в том, что современные процессоры осуществляют доступ к памяти не побайтно, а небольшими блоками, которые называют строками кэша. Обычно размер строки составляет 64 байта. Когда вы читаете какое-либо значение из памяти, в кэш попадает как минимум одна строка кэша. Последующий доступ к какому-либо значению из этой строки происходит очень быстро. Из-за того, что 16 значений типа int занимают 64 байта, циклы с шагами от 1 до 16 обращаются к одинаковому количеству строк кэша, точнее говоря, ко всем строкам кэша массива. При шаге 32, обращение происходит к каждой второй строке, при шаге 64, к каждой четвёртой. Понимание этого очень важно для некоторых способов оптимизации. От места расположения данных в памяти зависит число обращений к ней. Например, из-за невыровненных данных может потребоваться два обращения к оперативной памяти, вместо одного. Как мы выяснили выше, скорость работы при этом будет в два раза ниже.Пример 3: размеры кэшей первого и второго уровня (L1 и L2)
Современные процессоры, как правило, имеют два или три уровня кэшей, обычно их называют L1, L2 и L3. Для того, чтобы узнать размеры кэшей различных уровней, можно воспользоваться утилитой CoreInfo или функцией Windows API GetLogicalProcessorInfo. Оба способа так же предоставляют информацию о размере строки кэша для каждого уровня. На моей машине CoreInfo сообщает о кэшах данных L1 объёмом по 32 Кбайт, кэшах инструкций L1 объёмом по 32 Кбайт и кэшах данных L2 объёмом по 4 Мбайт. Каждое ядро имеет свои персональные кэши L1, кэши L2 общие для каждой пары ядер: Logical Processor to Cache Map: *--- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64 *--- Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64 -*-- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64 -*-- Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64 **-- Unified Cache 0, Level 2, 4 MB, Assoc 16, LineSize 64 --*- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64 --*- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64 ---* Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64 ---* Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64 --** Unified Cache 1, Level 2, 4 MB, Assoc 16, LineSize 64 Проверим эту информацию экспериментально. Для этого, пройдёмся по нашему массиву инкрементируя каждое 16-ое значение — простой способ изменить данные в каждой строке кэша. При достижении конца, возвращаемся к началу. Проверим различные размеры массива, мы должны увидеть падение производительности когда массив перестаёт помещаться в кэши разных уровней. Код такой: int steps = 64 * 1024 * 1024; // количество итераций int lengthMod = arr.Length - 1; // размер массива -- степень двойкиfor (int i = 0; i < steps; i++)
{// x & lengthMod = x % arr.Length, ибо степени двойки
arr[(i * 16) & lengthMod]++; } Результаты тестов: 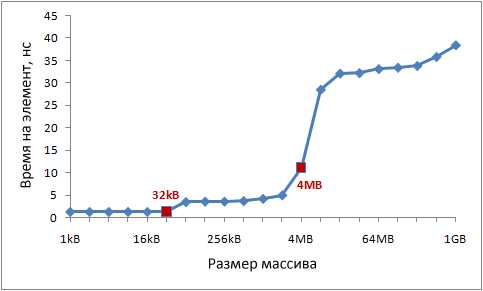
Пример 4: параллелизм инструкций
Теперь давайте взглянем на кое-что другое. По вашему мнению, какой из этих двух циклов выполнится быстрее? int steps = 256 * 1024 * 1024; int[] a = new int[2];// первый
for (int i = 0; i < steps; i++) { a[0]++; a[0]++; }// второй
for (int i = 0; i < steps; i++) { a[0]++; a[1]++; } Оказывается, второй цикл выполняется почти в два раза быстрее, по крайней мере, на всех протестированных мной машинах. Почему? Потому, что команды внутри циклов имеют разные зависимости по данным. Команды первого имеют следующую цепочку зависимостей:Во втором цикле зависимости такие:
Функциональные части современных процессоров способны выполнять определённое число некоторых операций одновременно, как правило, не очень большое число. Например, возможен параллельный доступ к данным из кэша L1 по двум адресам, так же возможно одновременное выполнение двух простых арифметических команд. В первом цикле процессор не может задействовать эти возможности, но может во втором.
Пример 5: ассоциативность кэша
Один из ключевых вопросов, на который необходимо дать ответ при проектировании кэша — могут ли данные из определённой области памяти храниться в любых ячейках кэша или только в некоторых из них. Три возможных решения:- Кэш прямого отображения, данные каждой строки кэша в оперативной памяти хранятся только в одной заранее определённой ячейке кэша. Простейший способ вычисления отображения: индекс_строки_в_памяти % количество_ячеек_кэша. Две строки, отображённые на одну и ту же ячейку, не могут находится в кэше одновременно.
- N-входовый частично-ассоциативный кэш, каждая строка может храниться в N различных ячейках кэша. Например, в 16-входовом кэше строка может храниться в одной из 16-ти ячеек составляющих группу. Обычно, строки с равными младшими битами индексов разделяют одну группу.
- Полностью ассоциативный кэш, любая строка может быть сохранена в любую ячейку кэша. Решение эквивалентно хеш-таблице по своему поведению.
Так как кэш L2 имеет 65 536 ячеек (4 * 220 / 64) и каждая группа состоит из 16 ячеек, всего мы имеем 4 096 групп. Таким образом, младшие 12 битов индекса строки определяют к какой группе относится эта строка (212 = 4 096). В результате, строки с адресами кратными 262 144 (4 096 * 64) разделяют одну и ту же группу из 16-ти ячеек и соревнуются за место в ней.
Чтобы эффекты ассоциативности проявили себя, нам необходимо постоянно обращаться к большому количеству строк из одной группы, например, используя следующий код: public static long UpdateEveryKthByte(byte[] arr, int K) {const int rep = 1024 * 1024; // количество итераций
Stopwatch sw = Stopwatch.StartNew();int p = 0;
for (int i = 0; i < rep; i++) { arr[p]++;p += K; if (p >= arr.Length) p = 0;
} sw.Stop();return sw.ElapsedMilliseconds;
} Метод инкрементирует каждый K-ый элемент массива. По достижении конца, начинаем заново. После довольно большого количества итераций (220), останавливаемся. Я сделал прогоны для различных размеров массива и значений шага K. Результаты (синий — большое время работы, белый — маленькое): 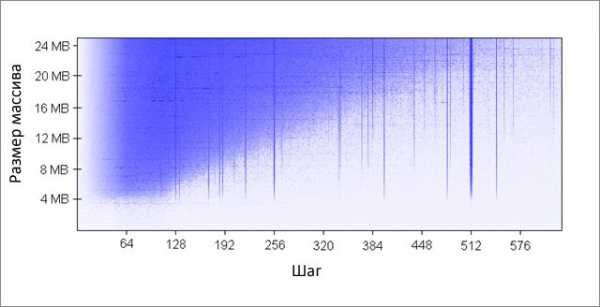
Синим областям соответствуют те случаи, когда при постоянном изменении данных кэш не в состоянии вместить все требуемые данные одновременно. Яркий синий цвет говорит о времени работы порядка 80 мс, почти белый — 10 мс.
Разберёмся с синими областями:- Почему появляются вертикальные линии? Вертикальные линии соответствуют значениям шага при которых осуществляется доступ к слишком большому числу строк (больше 16-ти) из одной группы. Для таких значений, 16-входовый кэш моей машины не может вместить все необходимые данные.
Некоторые из плохих значений шага — степени двойки: 256 и 512. Для примера рассмотрим шаг 512 и массив в 8 Мбайт. При этом шаге, в массиве имеются 32 участка (8 * 220 / 262 144), которые ведут борьбу друг с другом за ячейки в 512-ти группах кэша (262 144 / 512). Участка 32, а ячеек в кэше под каждую группу только 16, поэтому места на всех не хватает.
Другие значения шага, не являющиеся степенями двойки, просто невезучие, что вызывает большое количество обращений к одинаковым группам кэша, а так же приводит к появлению вертикальных синих линий на рисунке. На этом месте любителям теории чисел предлагается задуматься.
- Почему вертикальные линии обрываются на границе в 4 Мбайт? При размере массива в 4 Мбайт или меньше, 16-входовый кэш ведёт себя так же как и полностью ассоциативный, то есть может вместить все данные массива без конфликтов. Имеется не более 16-ти областей ведущих борьбу за одну группу кэша (262 144 * 16 = 4 * 220 = 4 Мбайт).
- Почему слева вверху находится большой синий треугольник? Потому, что при маленьком шаге и большом массиве кэш не в состоянии уместить все необходимые данные. Степень ассоциативности кэша играет тут второстепенную роль, ограничение связано с размером кэша L2. Например, при размере массива в 16 Мбайт и шаге 128, мы обращаемся к каждому 128-му байту, таким образом, модифицируя каждую вторую строку кэша массива. Чтобы сохранить каждую вторую строку в кэше, необходим его объём в 8 Мбайт, но на моей машине есть только 4 Мбайт.
Даже если бы кэш был полностью ассоциативным, это не позволило бы сохранить в нём 8 Мбайт данных. Заметьте, что в уже рассмотренном примере с шагом 512 и размером массива 8 Мбайт, нам необходим только 1 Мбайт кэша, чтобы сохранить все нужные данные, но это невозможно сделать из-за недостаточной ассоциативности кэша.
- Почему левая сторона треугольника постепенно набирает свою интенсивность? Максимум интенсивности приходится на значение шага в 64 байта, что равно размеру строки кэша. Как мы увидели в первом и во втором примере, последовательный доступ к одной и той же строке практически ничего не стоит. Скажем, при шаге в 16 байт, мы имеем четыре обращения к памяти по цене одного. Так как количество итераций равно в нашем тесте при любом значении шага, то более дешёвый шаг в результате даёт меньшее время работы.
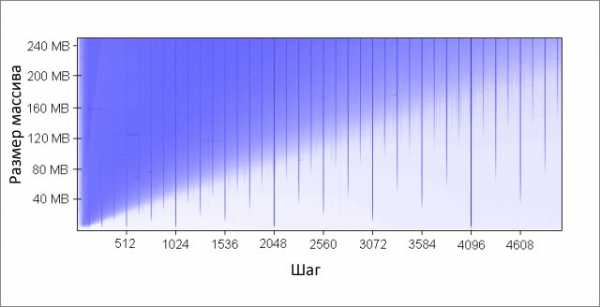
Пример 6: ложное разделение кэша
На многоядерных машинах можно столкнуться с другой проблемой — согласование кэшей. Ядра процессора имеют частично или полностью раздельные кэши. На моей машине кэши L1 раздельны (как и обычно), так же имеются два кэша L2, общие для каждой пары ядер. Детали могут различаться, но в целом современные многоядерные процессоры имеют многоуровневые иерархические кэши. Причём самые быстрые, но и самые маленькие кэши, принадлежат индивидуальным ядрам.Когда одно из ядер модифицирует значение в своём кэше, другие ядра больше не могут использовать старое значение. Значение в кэшах других ядер должно быть обновлено. Более того, должна быть обновлена полностью вся строка кэша, так как кэши оперируют данными на уровне строк.
Продемонстрируем эту проблему на следующем коде: private static int[] s_counter = new int[1024];private void UpdateCounter(int position)
{for (int j = 0; j < 100000000; j++)
{ s_counter[position] = s_counter[position] + 3; }}
Если на своей четырёхядерной машине я вызову этот метод с параметрами 0, 1, 2, 3 одновременно из четырёх потоков, то время работы составит 4.3 секунды. Но если я вызову метод с параметрами 16, 32, 48, 64, то время работы составит только 0.28 секунды. Почему? В первом случае, все четыре значения, обрабатываемые потоками в каждый момент времени, с большой вероятностью попадают в одну строку кэша. Каждый раз когда одно ядро увеличивает очередное значение, оно помечает ячейки кэша, содержащие это значение в других ядрах, как невалидные. После этой операции, все остальные ядра должны будут закэшировать строку заново. Это делает механизм кэширования неработоспособным, убивая производительность.Пример 7: сложность железа
Даже теперь, когда принципы работы кэшей для вас не секрет, железо по-прежнему будет преподносить вам сюрпризы. Процессоры отличаются друг от друга методами оптимизации, эвристиками и прочими тонкостями реализации.Кэш L1 некоторых процессоров может осуществлять параллельный доступ к двум ячейкам, если они относятся к разным группам, но если они относятся к одной, только последовательно. Насколько мне известно, некоторые даже могут осуществлять параллельный доступ к разным четвертинкам одной ячейки.
Процессоры могут удивить вас хитрыми оптимизациями. Например, код из предыдущего примера про ложное разделение кэша не работает на моём домашнем компьютере так, как задумывалось — в простейших случаях процессор может оптимизировать работу и уменьшить негативные эффекты. Если код немного модифицировать, всё встаёт на свои места. Вот другой пример странных причуд железа: private static int A, B, C, D, E, F, G;private static void Weirdness()
{for (int i = 0; i < 200000000; i++)
{ <какой-то код> } } Если вместо <какой-то код> подставить три разных варианта, можно получить следующие результаты:
Инкрементирование полей A, B, C, D занимает больше времени, чем инкрементирование полей A, C, E, G. Что ещё страннее, инкрементирование полей A и C занимает больше времени, чем полей A, C и E, G. Не знаю точно каковы причины этого, но возможно они связаны с банками памяти (да-да, с обычными трёхлитровыми сберегательными банками памяти, а не то, что вы подумали). Имеющих соображения на этот счёт, прошу высказываться в комментариях.
У меня на машине вышеописанного не наблюдается, тем не менее, иногда бывают аномально плохие результаты — скорее всего, планировщик задач вносит свои «коррективы».
Из этого примера можно вынести следующий урок: очень сложно полностью предсказать поведение железа. Да, можно предсказать многое, но необходимо постоянно подтверждать свои предсказания с помощью измерений и тестирования.
Заключение
Надеюсь, что всё рассмотренное помогло вам понять устройство кэшей процессоров. Теперь вы можете использовать полученные знания на практике для оптимизации своего кода. * Source code was highlighted with Source Code Highlighter. Метки:habrahabr.ru